Explainer Divergence Scores (EDS): Some Post-Hoc Explanations May be Effective for Detecting Unknown Spurious Correlations
Abstract
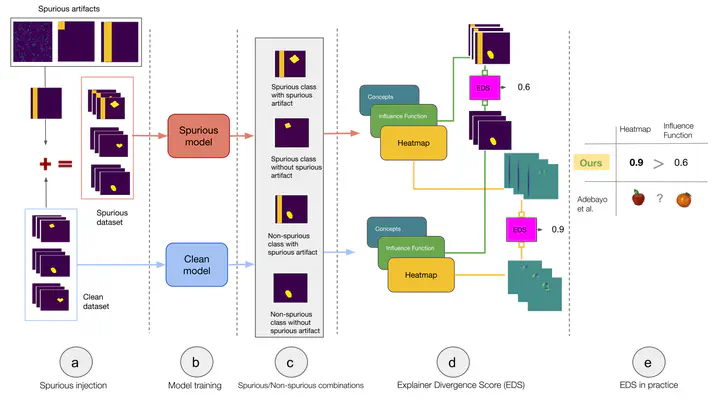
Recent work has suggested post-hoc explainers might be ineffective for detecting spurious correlations in Deep Neural Networks (DNNs). However, we show there are serious weaknesses with the existing evaluation frameworks for this setting. Previously proposed metrics are extremely difficult to interpret and are not directly comparable between explainer methods. To alleviate these constraints, we propose a new evaluation methodology, Explainer Divergence Scores (EDS), grounded in an information theory approach to evaluate explainers. EDS is easy to interpret and naturally comparable across explainers. We use our methodology to compare the detection performance of three different explainers - feature attribution methods, influential examples and concept extraction, on two different image datasets. We discover post-hoc explainers often contain substantial information about a DNN’s dependence on spurious artifacts, but in ways often imperceptible to human users. This suggests the need for new techniques that can use this information to better detect a DNN’s reliance on spurious correlations.